服务治理
服务治理
为什么要做服务治理
一个系统在开发之初,功能简单,规模较小。 随着业务需求的变化和增加, 系统的功能和规模会变得庞大。
将会出现以下问题:
- 维护、开发、部署将变得困难
- 水平扩展困难
- 功能及技术迭代困难 (注:技术迭代指的是替换使用的语言、第三方工具等)
为了解决上述的问题,我们将会采取分拆系统的方法,将一个庞大的系统拆分成N个小系统。
拆分会带来以下的好处:
- 独立部署,方便水平扩展
- 系统隔离
- 快速的迭代(每个系统可以根据业务场景来决定使用最优的开发语言和第三方工具)
但是,拆分并没有从根本上解决问题,随着业务发展,我们拆分出来的N个小系统会继续添加相关的业务, 随着时间的发展也变的复杂和庞大。我们又继续使用拆分的方案, 然后拆分出来的系统又随着业务的变化和发展, 开始从简单变得复杂,我们一遍又一遍做着重复拆分的事情。
解决问题的方法是:
在接到开发任务之初,将任务做成一个或者多个独立的服务单元(服务单元:请看下面注释), 每个服务单元单独部署和迭代开发,禁止添加其它非必要的功能。
注解:
服务单元:尽可能小的服务集合,只包含对于一个抽象属性的增删改查,杜绝添加其他相关联的功能和业务。
随之带来的问题是:
- 独立的服务单元越来越多,如何对服务单元做管理
- 如何做负载均衡
- 如何做服务信息的修改及快速生效
最开始的解决方案是由OP和RD配合来做的。 通过DNS,NGINX,CONFIG文件来配合完成任务。
DNS,NGINX都可以做负载均衡的功能。
DNS,NGINX,CONFIG都可以用来管理服务单元信息的变更
上述的方法,虽然可以解决问题,但是每次必须修改配置,然后重新加载配置才会生效。 无法实现立即生效,避免错误继续扩大的问题。为了解决这些问题,就要使用有效的服务治理方案。
服务治理
服务治理主要是对服务信息进行管理的一系列的系统。为了实现这个系统, 我们需要一个高可用、低延迟的数据存储工具。
经过筛选我们最终选择了zookeeper。 我们先来看下zookeeper官方的定义:
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
使用zookeeper原因:
- 公司已经有zookeeper集群,具备运维能力
- zookeeper 使用范围比较广,
- zookeeper watcher机制能够及时通知修改,保证信息一直
虽然,我们可以通过zookeeper来解决存储数据的问题, 但是服务的信息并不会自动出现在zookeeper中,我们需要开发一个关于服务治理的系统。
服务治理具备功能:
-
服务发现
主动注册和第三方注册两种服务发现方式,我们现在使用的是第三方注册的方式, 因为调用方和服务方都是PHP编写的,主动注册实现复杂
-
服务管理
服务状态的统计信息、服务信息管理、授权查看,在使用第三方注册时候,提供服务注册和修改功能
-
通信
异步通信和同步通信,现在只实现同步通信
-
访问控制
限制调用方使用的key对服务方访问频次、是否具有访问权限等检查
-
数据交互协议适配
调用方不用关注服务方提供服务使用的协议。目前支持http下json、yar-msgpack相互转换
如何去做
到目前为止,我找到解决问题的方法和需要实现的功能的。 根据上面的信息,我们给出了具体是的设计方案。如下图所示:
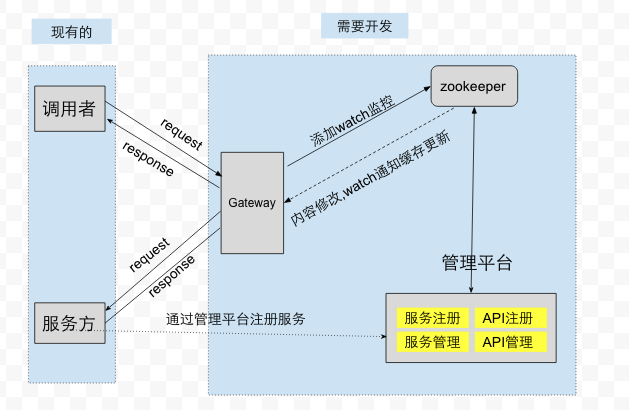
整个设计共分五部分:
-
调用者
通过HTTP或YAR访问Gateway, 将需要调用的服务信息和参数告诉 Gateway,
-
服务方
a) 提供服务
b) 将自己的信息通过管理平台注册到zookeeper中
1. 服务名、状态 2. 地址信息、机房、权重及状态 3. 服务下接口的列表 a) 接口名 b) 接口路径 c) 输出数据的编码(json或者yar-msgpack) d) 状态 -
Gateway
a) 请求的转发
b) 快速失败
c) 对发送的数据做编码(json或者yar-msgpack)
d) 负载均衡
e) 将服务和接口的信息缓存到内存中
-
管理平台
a) 服务及接口的注册
b) 服务及接口的查看
c) 服务及接口的修改
d) 统计信息查看
-
ZooKeeper
ZooKeeper在整个服务治理的设计中是最重要的组成部分。 在使用zookeeper之前。我们先来看下zookeeper存储数据的原理。 下面是zookeeper官方的介绍:
The name space provided by ZooKeeper is much like that of a standard file system. A name is a sequence of path elements separated by a slash (/). Every node in ZooKeeper’s name space is identified by a path.

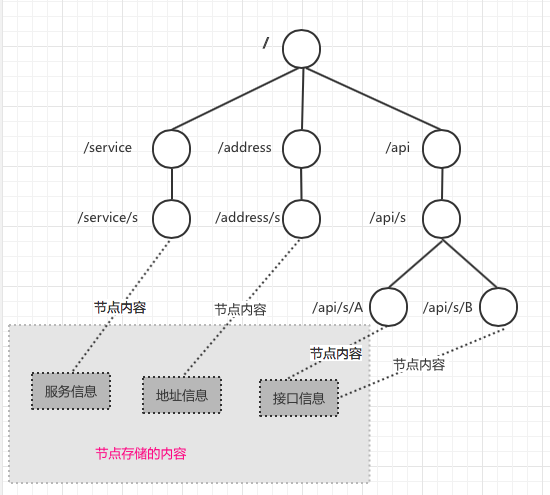
zookeeper就像一个树,用每一个”/{name}”表示节点及节点名。每一个节点可以有子节点和存储少量的内容。
我们在zookeeper中存储的信息有服务信息、地址信息、接口信息。具体格式如下:
服务信息:/service/{服务名}
地址信息:/address/{服务名}
接口信息:/api/{服务名}/{接口名}
为什么要将zookeeper中存储数据的结构设计为上面描述格式, 是因为zookeeper在watcher机制的处理中给出了
两个关于wather 通知使用的API(golang zk)
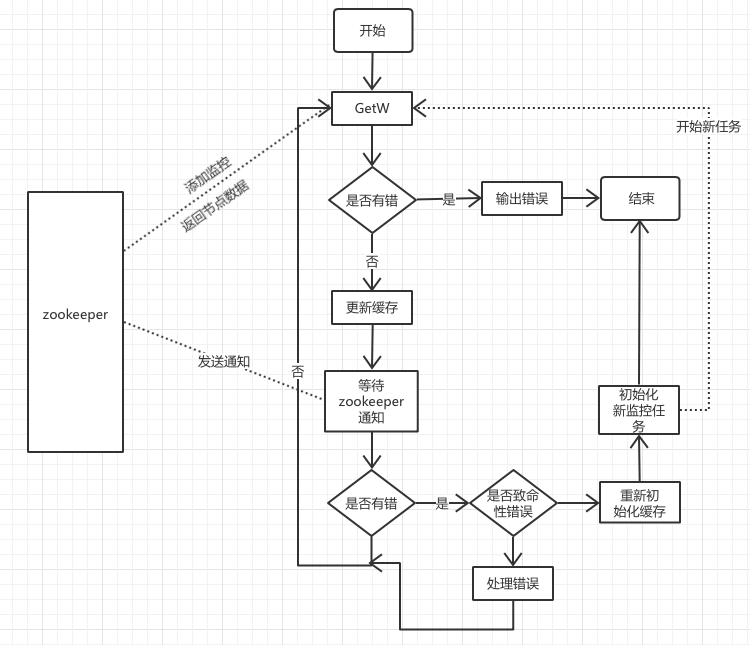
一个是关注子节点变化ChildrenW函数,另外一个是关注节点本身内容变化GetW函数。
我们设计的方案在实现上让每个节点功watcher更加简单。
我们现在来看一个具体的例子:假设有一个服务s,下面有A,B两个接口
出现的问题(如何保证缓存信息和zookeeper中的内容一致)
Gateway 为了做到低延迟和高可用性,在Gateway 中缓存zookeeper中的数据。 在Gateway中缓存数据的格式与zookeeper中的结构一致。 我们是如何保证缓存的信息是正确可用的, 就需要用到zookeeper的watcher机制。在zookeeper中内容中修改时, 通过watcher机制通知Gateway 来更新缓存
具体的设计如下图(具体实现的流程图在最后):
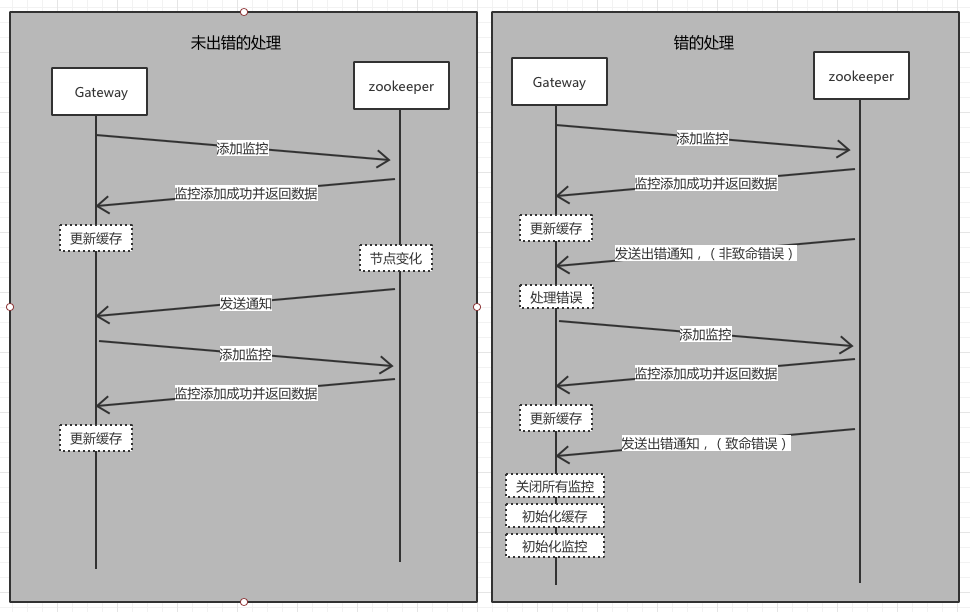
看了设计图可能会有下列的疑问:
-
为什么收到通知后不直接去更新缓存?
这个问题就需要了解zookeeper关于watcher机制的原理,zookeeper的watcher机制是一次性的, 在收到watcher的通知后,watcher就消失了。为了避免在更新缓存时zookeeper的 数据再次变化无法收到通知,因为这个时候watcher机制已经没有, zookeeper已经没有通知Gateway机制,这样缓存中的数据和zookeeper中的数据将会不一致。
-
为什么致命错误需要重新初始化缓存?
下面的介绍的内容会跟开发使用的语言和zookeeper的sdk有一定的关系。
开发语言:golang — SDK:samuel/go-zookeeper/zk
我们先来看下SDK是如何处理错误, 个人将SDK的错误分为非致命错误和致命错误错误两种(个人观点)。
非致命错误:ErrNoAuth、ErrAPIError、ErrAuthFailed等 致命错误:ErrSessionMoved、ErrSessionExpired等非致命错误是与zookeeper集群通信时,使用的参数及上下文环境出现问题返回的错误, 影响范围只有本次调用。
致命错误通常是与zookeeper集群的通信出现网络故障,影响与zookeeper集群的所有通信。 但是SDK(go-zookeeper)并不会在问题出现时刻立即报错, SDK会自动尝试建立新的可以使用的session, SDK在session建立成功后将给所有的watcher发送一个错误通知。
ErrSessionMoved: 是与zookeeper集群的某个实例session失效后, 下次与zookeeper成功建立session发送给所有watcher。
ErrSessionExpired:是与整个zookeeper集群session失效后, 下次与zookeeper成功建立session发送给所有watcher。
收到致命错误后,我们无法知道在于zookeeper集群session断开的时间段中, zookeeper中的数据数据变化情况。如果只是更新和新加, 我们可以在初始化的时候将节点的内容缓存即可, 但是如果有删除的话。我们就需要遍历所有的缓存内容来删除不需要的缓存。
具体实现的流程图: